GeniNav: Generative Model Driven Image-Goal Navigation via Imagination-Guided Consistency Flow Matching
Method Overview
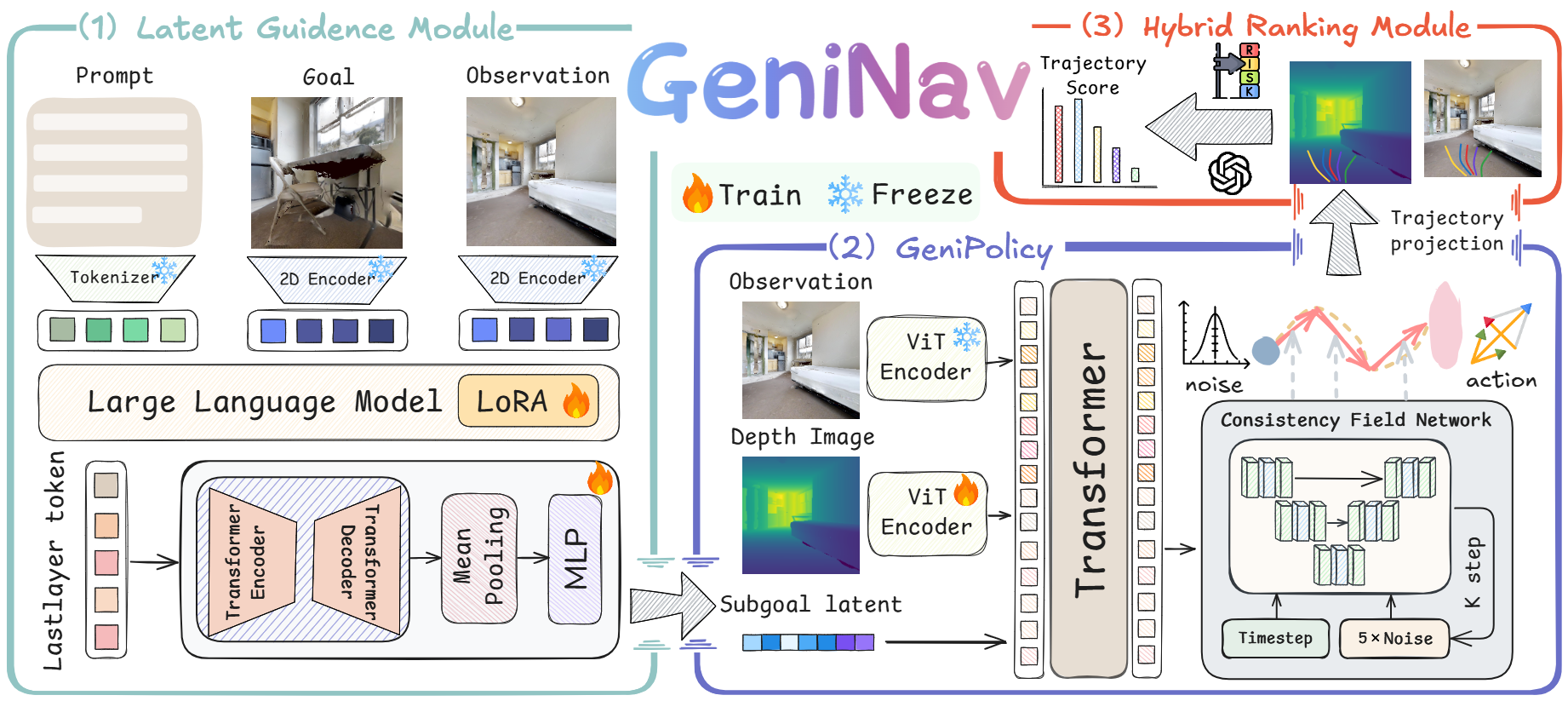
Overview of the GeniNav framework architecture.
Abstract
Image-goal navigation driven by generative models has recently shown strong potential owing to their ability to perform multi-modal reasoning and stable learning in continuous control spaces. Despite their promise, current methods still face several fundamental limitations. Many rely on pre-built priors and lack explicit mechanisms for trajectory evaluation, restricting generalization and goal alignment in map-free navigation. Moreover, current generative policies often face inefficiency or temporal inconsistency, resulting in temporally unstable motion. The absence of interactive, closed-loop benchmarks further limits fair and reproducible comparison. To address these issues, we propose GeniNav, a generative image-goal navigation framework that couples a VLM-driven latent subgoal imagination module for high-level semantic guidance with Multi-Segment Consistency Flow Matching (MS-CFM) for temporally smooth and dynamically coherent motion generation. A hybrid trajectory evaluation module further integrates semantic alignment and geometric feasibility to assess goal consistency. We also introduce a closed-loop simulation benchmark with a large-scale dataset spanning 176 scenes and 491.6 km for standardized training and evaluation. Extensive experiments in simulation and on real robots demonstrate the effectiveness of our method.